Optimizing Service Delivery with Upfront Data Availability
Abstract
The Availability Service is designed to enhance the user experience by delivering near real-time data from a cache that incorporates minimal refresh intervals, thereby reducing the load on downstream systems. The immediate availability of data enables users to make informed decisions when selecting a destination for specific services offered. This approach significantly increases client responsiveness, offering data that is effectively real-time and more efficient than retrieving information directly from downstream systems.
Introduction
The proposed approach encounters challenges when dealing with dependent services that experience high latency or availability issues due to unavoidable external factors. Such circumstances can prove frustrating for end users, leading to a suboptimal customer experience. Addressing these challenges by developing mechanisms that ensure a seamless customer journey is imperative.
Similar challenges arise in any flow that depends on data being available from a downstream service. The user flows significantly affected these downstream services, harming performance and leading to downtime. Consequently, this also impacted other flows that relied on data from the same service. The issue became especially noticeable during a sudden surge in user requests directed at the system.
Challenges to overcome
A comprehensive approach has been developed to address several issues that will enhance the overall customer user experience.
1. Mitigate the load on downstream services by minimizing the number of API calls, using only essential requests to refresh data, instead of sending requests downstream for every interaction.
2. Facilitate faster responses to users by retrieving data from internal cached storage, thereby avoiding the delays associated with downstream response times and network latencies.
3. Implement upfront projections of data concerning availability views to provide users with a clearer perspective based on their selected locations.
Initial Flow

Revamped Flow

Architecture
Initially, the design had sync flows, which internally invoked downstream APIS on each request to pull the latest availability data, causing contention and bottlenecks, thus impacting user flows. The proposal was to decouple the flows to easily support peak load without affecting services. Further exploration of the usage of the CQRS design pattern[1], to solve the use case where the provider service writes data to its storage and availability read APIs reads from the availability database.
The master SQL server should be used for the write operation, and the Read-Scale-Out[2] option, available using read replicas, should be used for the read operation. Read-Scale-Out[2] uses the capacity of a read-only replica instead of sharing the read-write replica (also known as the primary database). This way, read-only workloads, like reports, queries, and API pages, are isolated from the main read-write workload code units.
CQRS stands for Command and Query Responsibility Segregation, a pattern that separates read and update operations for a data store. Implementing CQRS in an application can maximize its performance, scalability, and security. The flexibility created by migrating to CQRS allows a system to evolve better over time and prevents update commands from causing merge conflicts at the domain level.
Let us get into detail to understand how this was achieved.
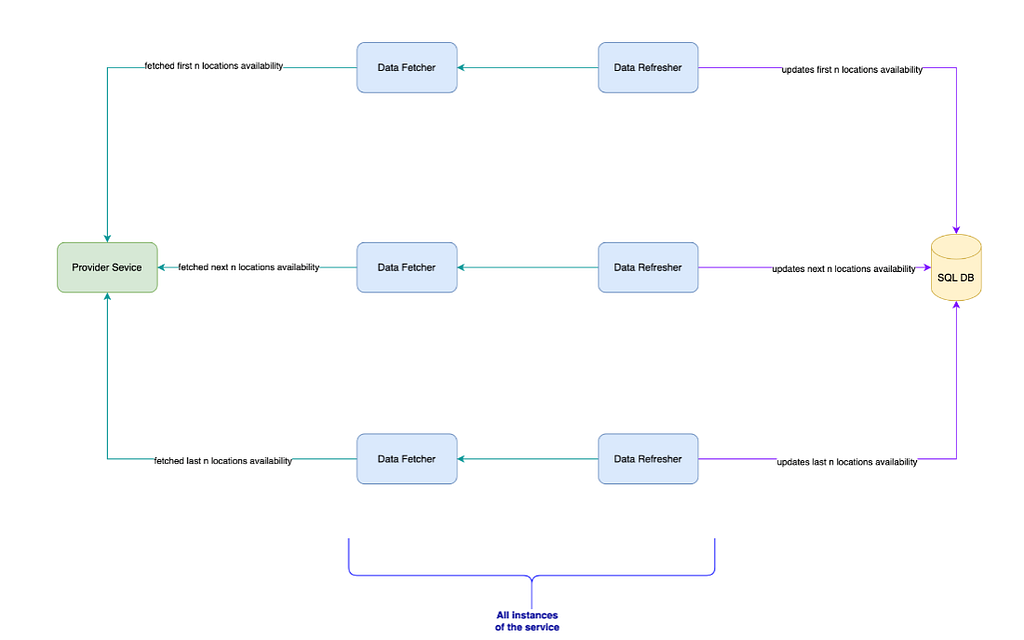
The above-revamped flow depicts the new architecture flow with available service to enhance user experience. Before digging deeper, let us touch upon the key points used in the design.
· Location: Actual physical, demographic information where a given service is available for the user to book.
· Scheduler: Trigger at scheduled interval, which executes the refresh task
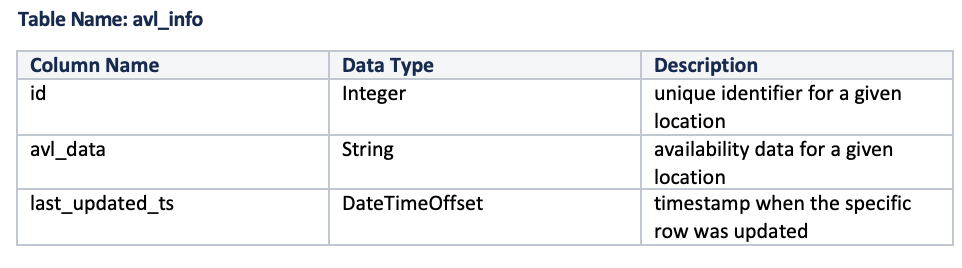
· Provider Service: Actual Service, which manages data availability for locations based on protocols and standards defined for communication.
· Data Refresher: This task runs parallel on all instances to refresh the current availability data at periodic intervals triggered by the scheduler.
· Data Fetcher: Flow connects to the downstream Provider Service to fetch the required availability data.
· Data Extractor: This flow is responsible for fetching inventory information from downstream services based on protocols and standards defined for communication.
· Availability Flow: This flow pulls availability data from the availability database using the CQRS pattern, along with some hydration of data from external dependencies.
The Availability Service primarily sends required data to clients with data present within the system. Multiple jobs refresh the data, minimizing the amount of stale data served.
Flow has refresher jobs, which target pulling data for certain locations and updating it in the DB before the data becomes stale. There is some tolerance to show stale data up to a threshold of time not breached. Once the threshold has crossed, the availability is marked as STALE so that clients can infer the state of data being returned. Since serving as a cache for the frequently changing real-time data, it is essential to ensure that the data for all locations is refreshed as quickly as possible. To achieve this, a way to distribute a certain number of locations to each instance of the availability service has been designed so that each instance can concurrently work on a fixed set of locations and the exact location does not get picked by concurrently executing processes. The idea behind implementing this is to use a TTL set whenever the data is updated in the database and the processes that must refresh the data from the picked set of locations for which the TTL has expired.
The schema used for distributing locations across instances parallelly is as below

The schema used for storing the availability data
Opting for SQL Server facilitates load distribution across instances and enables caching of data availability due to the following reasons.:
· Row Lock: SQL Server provides a query hint to specify that the SQL server engine takes row locks when page or table locks are ordinarily taken. When specified in transactions operating at the SNAPSHOT isolation level, row locks are not taken unless ROWLOCK is combined with other table hints that require locks, such as UPDLOCK and HOLDLOCK. ROWLOCK cannot be used with a table that has a clustered column store index.
· Read Past: Specifies that the Database Engine does not read rows locked by other transactions. When READPAST is specified, row-level locks are skipped, but page-level locks are not skipped. The Database Engine skips past the rows instead of blocking the current transaction until the locks are released. For example, assume table T1 contains a single integer column with 1, 2, 3, 4, and 5 values. If transaction A changes the value of 3 to 8 but has not yet been committed, a SELECT * FROM T1 (READ PAST) yields values 1, 2, 4, and 5. READPAST is primarily used to reduce locking contention when implementing a work queue that uses an SQL Server table. A queue reader that uses READPAST skips past queue entries locked by other transactions to the next available queue entry without waiting until the other transactions release their locks.
Reason for choosing the SQL server hints paradigm:
· It helps with easy load distribution across all computes for efficient processing with minimalist time.
· Redundant and Stateless flow: Each compute will have the ownership to refresh the data for certain locations based on certain algorithms, but it can be affected once any computes go down. This approach helps with easy load redistribution across available computes without manual intervention.
SQL Query is used to pick locations that need to be refreshed across instances parallelly.
Pick Locations for Refresh
WITH EligibleLocations AS (select top (?) id, ttl from avl_ttl WITH (ROWLOCK, READPAST) where ttl <= sysutcdatetime());
UPDATE EligibleLocations SET ttl = DATEADD(SECOND, ?, sysutcdatetime()), last_update_ts = sysutcdatetime() OUTPUT inserted.id, DATEDIFF(SECOND, sysutcdatetime(), deleted.ttl) updateTimeLag;
Above is the diagrammatic representation of the distribution of locations across computes to parallelly execute the data refresh without having the exact locations picked up by different computes. Data Refresher runs on every compute, which internally selects the locations that must be picked for the current job run. Suppose there are 1000 locations, and 10 computes running out of 500 locations, data is stale (TTL has expired), and data needs to be refreshed. In that case, the data refresher picks 50 locations on each compute and calls the data fetcher for these selected locations for the latest availability data from the downstream parallelly based on certain thread pool configurations, which limits the number of parallel calls to the downstream. Once the data is fetched, the data refresher updates the availability data to the column avl_data of table avl_data in SQL DB corresponding to the location info. Also, resilience4j rate limiters and circuit breakers limit the number of requests sent downstream when the downstream is slow or unavailable.
Futuristic Design — Moving away from a poll-based model to a push-based model
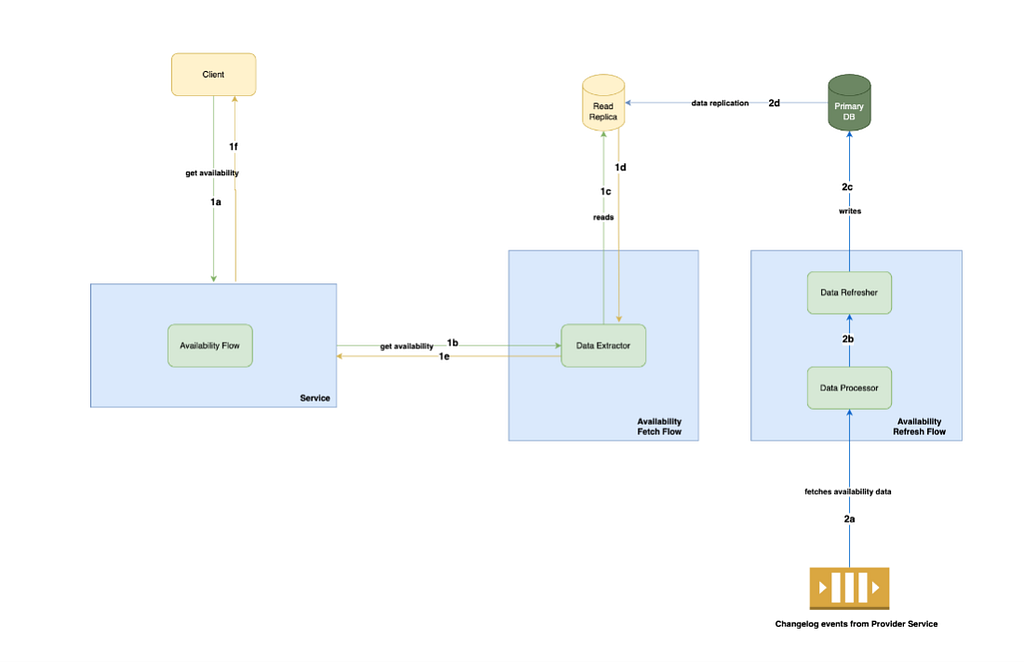
Downstream provider services have limitations.
· Allow only data sync via API polling flows and not via asynchronous changelog events, which are limited to not proceeding with the eventing approach. Once the providers start emitting events, as there will be a change in availability, flows can start consuming the events from the queue and processing the data in real time based on events being synchronized from the provider service.
· A pull-based model is undesirable due to the additional complexity of the data polling jobs.
Data Processor: Consumes events from provider service and forward related events based on filtering and parsing the required information
Observations with the usage of availability Flow in the current system
· Drastic reduction of load on downstream systems
· Even during peak load, the throughput of requests to downstream remains constant
· Using resilience4j rate limiters, bulkhead, and circuit breakers helped make the system most robust and resilient.
· Enhanced customer experience as the data was upfront, ready to be served, and available for users.
· Overall, it improved the health of our system as it minimized failures and other issues that throttle load during peak hours.
References
[1] https://docs.microsoft.com/en-us/azure/architecture/patterns/cqrs
Optimizing Service Delivery with Upfront Data Availability was originally published in Walmart Global Tech Blog on Medium, where people are continuing the conversation by highlighting and responding to this story.
Introduction to Malware Binary Triage (IMBT) Course
Looking to level up your skills? Get 10% off using coupon code: MWNEWS10 for any flavor.
Enroll Now and Save 10%: Coupon Code MWNEWS10
Note: Affiliate link – your enrollment helps support this platform at no extra cost to you.
Article Link: Optimizing Service Delivery with Upfront Data Availability | by Rakesh Pandit | Walmart Global Tech Blog | Mar, 2025 | Medium
1 post - 1 participant
Malware Analysis, News and Indicators - Latest topics

Sp123
"An underestimated security threat to organizations is employee apathy and burn out."
